Vector search in Dungeons and Dragons
If you've ever tried searching for something in a SQL database using a LIKE %query% query, you know you'll only find rows that literally contain the character sequence specified in query.
If you search your magic item database for "Phoenix Blade", but instead of the exact words you write "Sword of the Phoenix" or even more generically "burning magic sword", the database will reply with a dry "No results".
Semantic, or vector, search understands your intentions and not just your words. Instead of looking for exact character matches, it looks for matches of meaning.
In this article, we'll implement a vector search system from scratch in PHP, using it for the only purpose that really matters: finding the right spell to pulverize an army of goblins.
Keyword vs Vector search
Imagine being in an arcane library, surrounded by thousands of spells, not knowing which one to use. You need a spell to stop a goblin horde.
The classic keyword approach You go to the librarian (the Database) and ask: "Give me something for a fire explosion". The librarian, a very diligent golem but lacking reasoning, scans the titles.
- Search "explosion".... Found: *"Explosion of magical confetti"*. (Useless).
- Search "fire".... Found: *"How to light a campfire"*. (Useless).
The real spell you needed was "Fireball", but since you didn't say the word "Ball", the librarian spreads his arms in dismay.
The vector (semantic) approach Now imagine a different librarian, a friendly Mind Flayer capable of reading your thoughts. You think: "I want to go boom and burn the goblins". He understands the abstract concept (Damage + Area + Fire) and immediately brings you the Fireball scroll.
This is the heart of vector search: transforming words into mathematical concepts and calculating their proximity. "go boom" and "fireball" are different representations, but conceptually similar. A vector system knows this.
Vectors
But how does a computer understand concepts? Simple: by transforming them into numbers.
Let's think about the Character Sheet in our favorite RPG. How do you describe a hero so that rules can handle them? You use statistics.
Imagine having only 2 stats: Strength and Intelligence and let's try to describe three heroes:
- Barbarian: Strength 18, Intelligence 6.
- Wizard: Strength 6, Intelligence 18.
- Warlock: Strength 8, Intelligence 16.
If we draw these values on a Cartesian plane, assigning Strength to X and Intelligence to Y, each character becomes a point. If we now draw an arrow starting from the origin (0,0) to the point representing the character, we have defined a vector.
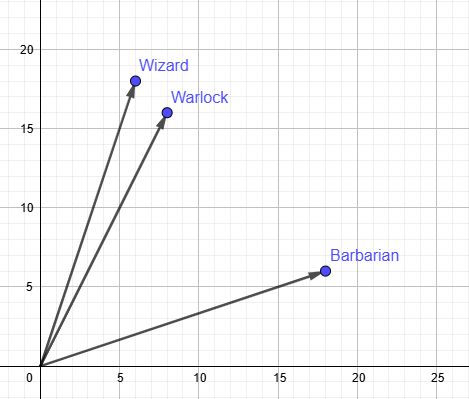
Distance is meaning
Looking at the Cartesian plane we just drew, we notice something immediately: The Wizard's point (6, 18) is geometrically very close to the Warlock's (8, 16). The Barbarian's point (18, 6) is very far from both.
In this two-dimensional space, geometric proximity represents conceptual similarity.
The multiverse
In the real world, however, we don't use just 2 dimensions (Intelligence and Strength) but thousands. For example, OpenAI's text-embedding-3-small model, which helps us describe a concept, manages to do so using 1536 dimensions.
It's a bit like creating a character sheet with thousands of stats: not just Strength or Dexterity or Intelligence, but also "Fire-ness", "Tendency to Heal", "Area Damage", "Probability of being a Goblin", and 1500+ other characteristics, each with its precise decimal value.
So every sentence you write is transformed into this list of 1536 float numbers. This process is called Embedding.
- "Dog" becomes
[0.12, 0.98, -0.05, ...] - "Puppy" becomes
[0.15, 0.95, -0.02, ...] - "Car" becomes
[0.01, 0.02, 0.99, ...]
The resulting vector cannot be represented on a Cartesian plane, but will reside in a multiverse of 1536 dimensions.
Mathematically we won't have any problem, 2 dimensions or 1536 dimensions are just numbers; in the end, the "Dog" vector will be very close to "Puppy" and far from "Car".
Cosine Similarity
How do we calculate if two vectors are similar? In a high-dimensional vector space, we prefer to use Cosine Similarity instead of simple distance. Basically, we measure the angle between the two vectors.
- If two arrows point in the same direction, the angle is 0° (Cosine = 1). Maximum similarity.
- If they point in opposite directions, the angle is 180° (Cosine = -1). Opposite concepts.
- If they are perpendicular, the angle is 90° (Cosine = 0). No correlation.
We use the angle because it has been observed that text length influences vector length; this means a whole book about Dragons might have a much longer vector than a tweet about Dragons, but both will have a similar "angle" because they talk about the same topic.
Implementation in PHP
Let's try to build a search engine for our library. The goal is to find the right spell starting from a vague description.
1. The database
Let's create a spell database by defining a spells.json file:
[
{
"nome": "Fireball",
"descrizione": "A bright streak flashes from your pointing finger... blossoms with a low roar into an explosion of flame."
},
{
"nome": "Cure Wounds",
"descrizione": "A creature you touch regains a number of hit points equal to 1d8."
},
{
"nome": "Invisibility",
"descrizione": "A creature you touch becomes invisible until the spell ends. Anything the target is wearing or carrying is invisible as long as it is on the target's person."
}
]2. Embeddings
To give meaning to spells (and thus transform them into vectors) we use the OpenAI API:
const OPENAI_API_KEY = '...'; // TODO: use your API key generated by registering on OpenAI
public function getEmbedding(string $text): array {
$ch = curl_init();
$data = [
'input' => $text,
'model' => 'text-embedding-3-small'
];
curl_setopt($ch, CURLOPT_URL, 'https://api.openai.com/v1/embeddings');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($data));
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'Authorization: Bearer ' . OPENAI_API_KEY,
'Content-Type: application/json'
]);
$result = curl_exec($ch);
curl_close($ch);
$response = json_decode($result, true);
if (!isset($response['data'][0]['embedding'])) {
throw new Exception("API Error: " . json_encode($response));
}
return $response['data'][0]['embedding'];
}Now that we have the function, let's enrich the spells file with vectors for each item. This is an expensive operation that must be done only once and then saved to file.
// Reads spells from json file
$spells = json_decode(file_get_contents('spells.json'), true);
// Calculates embeddings for each spell
echo "Indexing in progress...\n";
foreach ($spells as &$spell) {
// We create an embedding that combines name and description
$text = "Spell: " . $spell['nome'] . ". Effect: " . $spell['descrizione'];
$spell['vector'] = getEmbedding($text);
}
// Saves to file
file_put_contents('spells.json', json_encode($spells));At this point, our spells.json file will contain, besides name and description, also the vector for each spell.
3. Calculating Cosine Similarity
The mathematical formula to calculate similarity between two vectors $A$ and $B$ is:
$$\text{similarity} = \frac{A \cdot B}{|A| |B|}$$
It's much easier than it looks. Simply put:
- Dot Product ($A \cdot B$): We sum the products of corresponding components. If both vectors have high values in the same dimensions, this number grows.
- Magnitude ($|A|$ and $|B|$): We calculate the "length" of each vector.
- Division: By dividing the dot product by the product of lengths, we "normalize" the result. This allows us to ignore how long the text is and focus only on direction (meaning).
function cosineSimilarity(array $vecA, array $vecB): float {
// Vectors MUST have the same dimension
if (count($vecA) !== count($vecB)) {
throw new Exception("Dimension mismatch");
}
$dotProduct = 0;
$magnitudeA = 0;
$magnitudeB = 0;
foreach ($vecA as $i => $valA) {
$valB = $vecB[$i];
$dotProduct += $valA * $valB;
$magnitudeA += $valA * $valA;
$magnitudeB += $valB * $valB;
}
$magnitudeA = sqrt($magnitudeA);
$magnitudeB = sqrt($magnitudeB);
if ($magnitudeA * $magnitudeB == 0) return 0;
return $dotProduct / ($magnitudeA * $magnitudeB);
}4. The search engine
// Reads spells and their vectors from json file
$spells = json_decode(file_get_contents('spells.json'), true);
// User Query
$query = "I want to heal my injured friend";
echo "\nPlayer searches: \"$query\"\n";
// Query Embedding
$queryVector = getEmbedding($query);
// Search (we iterate all records, not efficient for large datasets)
$results = [];
foreach ($spells as $spell) {
$score = cosineSimilarity($queryVector, $spell['vector']);
$results[] = [
'nome' => $spell['nome'],
'score' => $score
];
}
// Sorting results
usort($results, fn($a, $b) => $b['score'] <=> $a['score']);
// Output
foreach ($results as $res) {
$perc = round($res['score'] * 100, 1);
echo "[{$perc}%] {$res['nome']}\n";
}The result? Cure Wounds will be at the top with a high score (e.g. 0.85), while Fireball will be at the bottom, because mathematically "healing" and "burning" are vectors pointing in different directions.
But in real life?
Our PHP script works well for a few data points, but comparing the query vector with millions of records would be too slow (a giant foreach loop means O(N) complexity which grows linearly with data growth).
For this reason, in production, we use Vector Databases (like Qdrant, Pinecone, or pgvector on PostgreSQL). These systems don't just loop through all rows, but use smart spatial indexes (like HNSW) to narrow the search only to records with "close" meaning, making the query instant even on millions of documents.
Conclusion
Vector search is not black magic, it's just geometry applied to language. It allows us to build more human interfaces, which understand intent and tolerate inaccuracy.
Now that your grimoire is intelligent, you have much better chances against those goblins.